DeepSeek V3:中國新創如何以1/11成本挑戰全球頂尖AI模型?

DeepSeek V3:中國新創如何以1/11成本挑戰全球頂尖AI模型?
AI 圈近期出現了一個很火紅的新創 DeepSeek,這是一支由清華北大應屆畢業生組成的團隊,他們僅用 1/11 的算力就訓練出了一個超越 Llama 3 效能的開源模型。
▍DeepSeek 為什麼會突然爆紅?
最近自己也一直在關注 AI 領域相關的進展跟又有那些技術突破,就在去年年底,對岸這家新創公司 DeepSeek 發布最新模型 DeepSeek V3,吸引人注意的地方是,它以驚人的成本效益和技術突破,震撼了全球 AI 圈。
大家都知道,自 2022 年以來,美國通過《晶片與科學法案》及其他相關法案,對中國的半導體產業實施了一系列出口管制。這些措施包括限制對中國出口先進的半導體製造設備和技術,特別是針對 10 奈米以下的製程設備和高性能計算晶片。
所以 DeepSeek V3 的成功,才會讓美國這些科技巨頭感到驚艷。OpenAI CEO Sam Altman 在 X 上還發表了一篇似乎暗指 DeepSeek 和其他競爭者的貼文,寫道:
「it is (relatively) easy to copy something that you know works. it is extremely hard to do something new, risky, and difficult when you don’t know if it will work.(抄襲某個成功的東西(相對)容易,但創造一些全新的、有風險且困難的事物,當你無法確定是否會成功時,則極其困難。)」
Sam Altman 會這麼說,大概也是認為 DeepSeek 某種程度「可能」拿了 GPT-4 生成的公開數據集作為訓練資料吧 XD
By the way, 這不是我這次關注 DeepSeek V3 的地方,個人對於對岸在硬體受限的狀況下,還可以搞出來這樣的研究,不僅公開了技術報告,還在 Hugging Face 上開源,對於能有這樣的創新突破與思維,其背後的團隊相當感興趣。
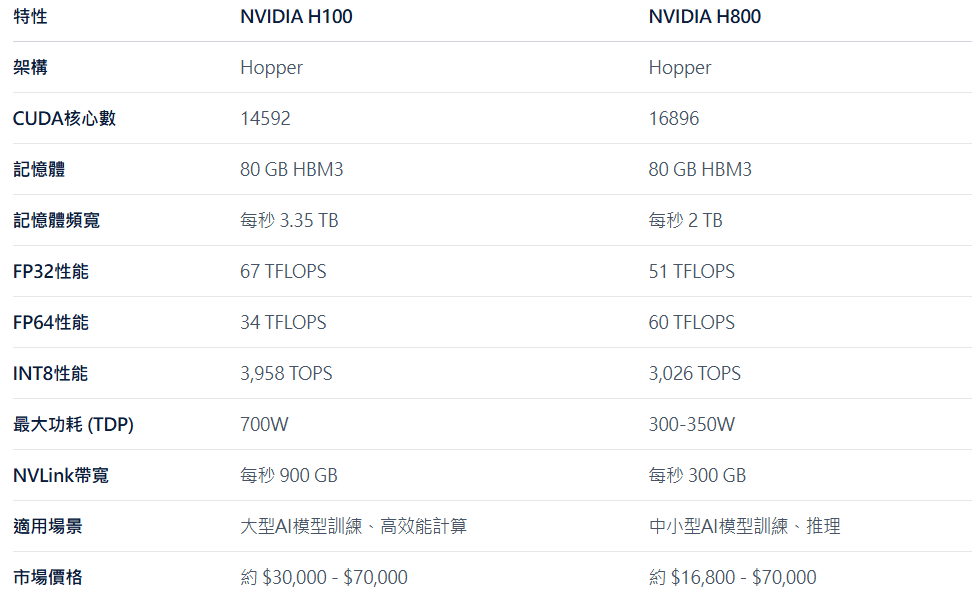
畢竟這款擁有 671B 的大模型,在 Pre-training 階段只用了 2 個月、2048 張 H800 顯示卡及 557.6 萬美元的成本就完成訓練,卻能與 GPT-4 和 Claude-3.5 等世界頂尖的閉源模型並駕齊驅。
這樣說可能沒感覺,換個比喻,GPT-4 的訓練成本高達 10 億美元,而 Claude 3.5 Sonnet 則成本是 5 億美元,相較於 GPT-4,DeepSeek 足足節省了近 17 倍的成本,這凸顯這篇技術報告在「效率成本」上的驚人進展。
▍一隻年輕且充滿活力的開發團隊
DeepSeek 團隊最大的特點就是「年輕」。團隊成員多為清華大學、北京大學等中國頂尖大學的在學生或應屆畢業生。
前幾天有一篇對岸的新聞,小米 CEO 雷軍開千萬年薪挖 DeepSeek 研究員羅福莉的新聞,這不只科技圈,也讓很多人對 DeepSeek 究竟是一隻怎樣的團隊?有怎樣的組織架構?感到特別好奇?

先來說說我科普到的一些關於 DeepSeek 的消息,CEO 梁文鋒 畢業於浙江大學,主修電子工程,專注於人工智慧領域。
在創立 DeepSeek 之前,梁文鋒曾在金融科技領域工作,特別是在量化投資和私募基金方面積累了豐富的經驗。他的管理風格相對低調,注重團隊的創新和實驗。鼓勵年輕的技術人才發揮創造力,並在公司內部建立了扁平化的管理結構,促進了團隊成員之間的直接交流。
所以,早在 2023 年 5 月,DeepSeek 剛剛宣佈要做大模型,還沒發佈成果的時候,梁文鋒在接受 36 氪旗下「暗湧」採訪時就透露過招人標準。
他只「看能力,而不是看經驗。」,而且,我們的核心技術崗位,基本以應屆和畢業一兩年的人為主。
從 DeepSeek 後續陸續發表的論文名單中也可以看出,團隊的組成確實都是,博士在讀、應屆以及畢業一兩年的成員佔很大一部分。即使是團隊 leader 也偏年輕化,以畢業 4-6 年的為主。這組織形態很像當年 OpenAI 新創時的那種氛圍,所以,也很多人把 DeepSeek 看成是中國的 OpenAI。
查了一下大陸這些學霸的背景與投稿,在人工智能領域頂級國際會議 ACL 上都有很多產出與貢獻,不得不說對岸年輕人內卷文化,不是我們能夠想像的。
▍技術突破與創新
DeepSeek V3 他們是把研究的論文與方法都公開,其中蠻多涉及到艱深數學模型與演算法,這部分我就不多做著墨了。這篇我是搭配著 AI 伴讀,大致上把一些看到的重點列出來做個紀錄跟大家分享。
DeepSeek V3技術文件提到,其採用多頭潛在注意力(Multi-head Latent Attention,MLA)和 MoE(混合專家) 架構,雖然 DeepSeek V3 的模型規模高達 6,710 億參數,但每次推論只會啟動 370 億參數,大幅降低推論成本並提升效能。同時,透過全新的多 Token 預測訓練目標(Multi-token Prediction Training Objective),DeepSeek V3 在語言生成與推論能力方面有所突破,也在穩定性與效能間取得平衡。
與其他模型相比,DeepSeek V3 在知識型基準測試 MMLU、GPQA,以及軟體工程基準測試 SWE-Bench Verified 上,分數接近 Claude-3.5-Sonnet-1022。在中文能力上逼近阿里巴巴的 Qwen2.5-72B 模型,數學能力則在 Math-500 測驗中則以 90.2 分位居第一。
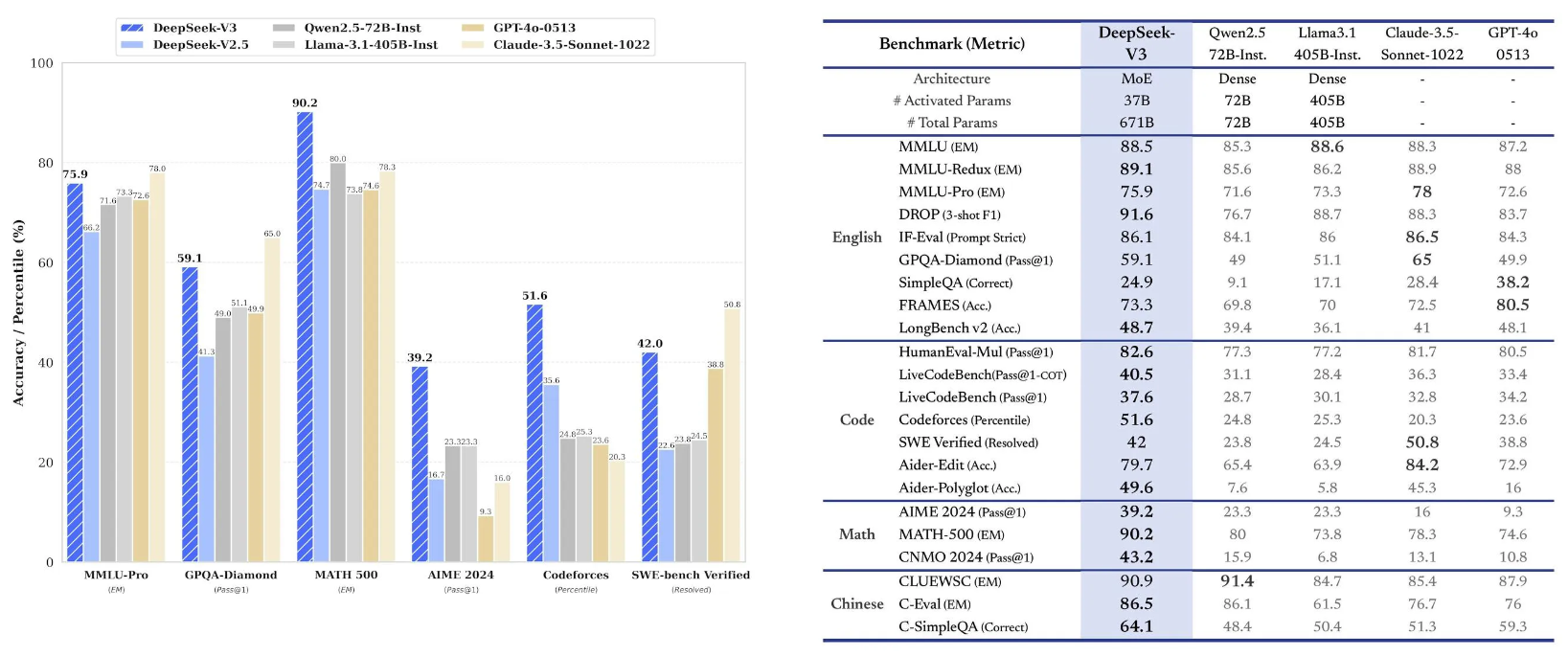
DeepSeek-V3 使用含 14.8 兆個 token 的資料集上進行訓練,模型架構採用的是 DeepSeekMoE(混合專家)以及多頭注意力機制,外加了負載平衡策略,以確保在不影響整體模型效能下,動態調整專家的負載。
以下就幾個關鍵的技術做概要說明:
-
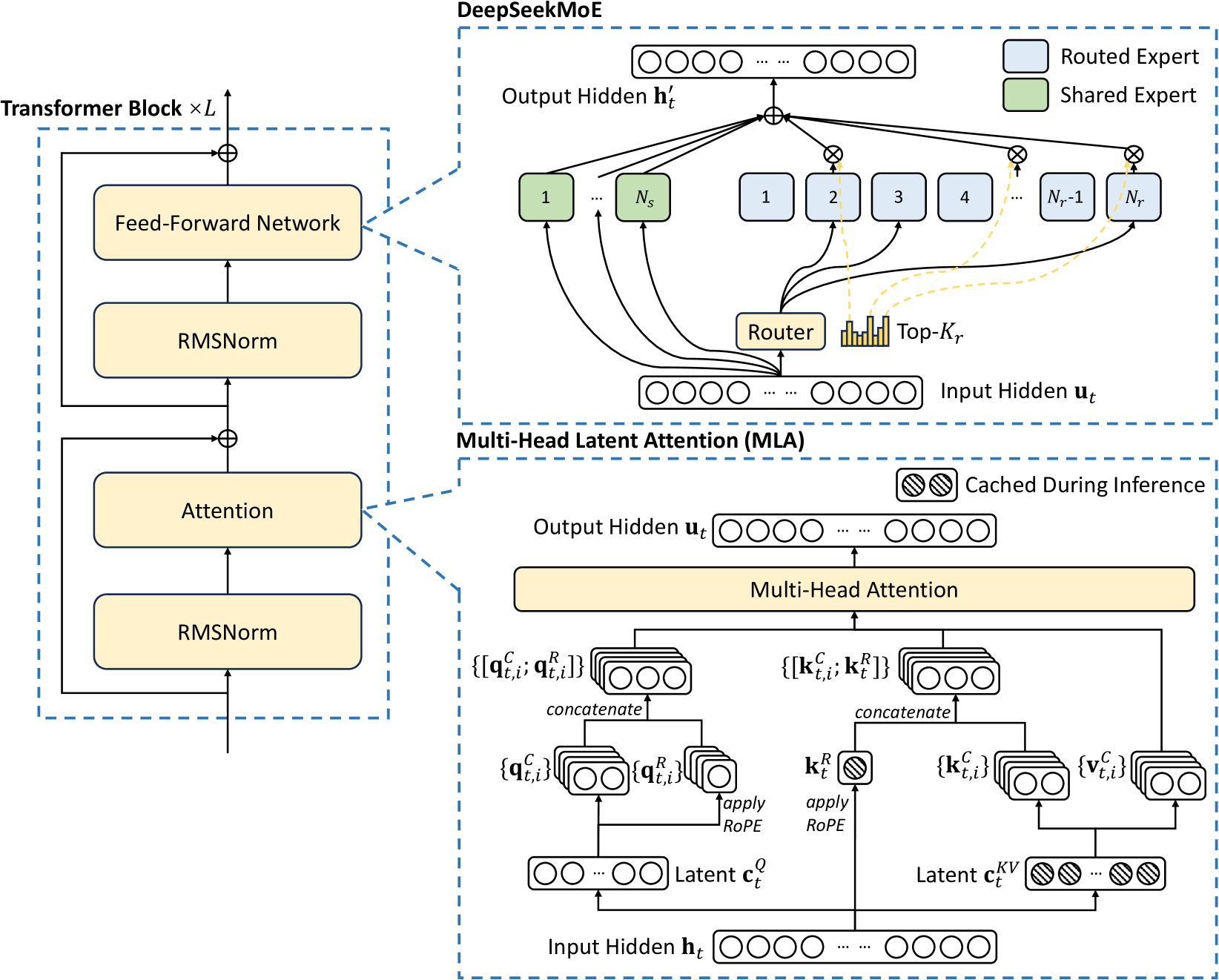
Multi-head Latent Attention(MLA)
MLA 是一種創新的注意力機制,旨在提升模型對長文和複雜語境的理解能力。透過多頭設計,MLA能同時關注不同語義層次,並有效處理多樣化的語境訊息。
DeepSeek V3 沿用 DeepSeek V2 的 MLA 和 DeepSeekMoE 架構。MLA 架構來實現高效推理,此架構在 DeepSeek V2 中已驗證其效能,MLA 被證明可以減少 93.3% 的 Key-Value ,簡單來講就是把 Transformer 模型的 Attention 層,輸入經由映射至 KV,由於資料被壓縮過後,所以在推論過程不需要花費大量的快取,所以可以節省效率。
-
DeepSeekMoE
再來是前饋神經網路導入他們設計的 DeepSeekMoE,其核心在於每次僅激活部分專家(如370億參數),從而大幅降低運算成本並提升效能。
據 DeepSeek 稱可以節省 42.5% 的訓練成本,因為使用專家系統,由路由專家 Routed Expert 和 Shared Expert 共享專家來提高專家專業化的潛力。簡單來說專家系統的安排,模型每次都可以更準確的知識獲取;以及隔離一些共享專家,以減輕路由專家之間的冗餘知識,也就是雜訊。
-
輔助損失自由負載平衡(Auxiliary-Loss-Free Load Balancing)
大致上理解是透過動態分配輸入到不同專家(Experts),自動實現資源利用的均衡,而無需額外的輔助損失干預。它不僅提升了模型的計算效率和穩定性,還避免了多目標優化帶來的複雜性,使得大型稀疏架構(如MoE)能以更低的成本發揮更高效能
-
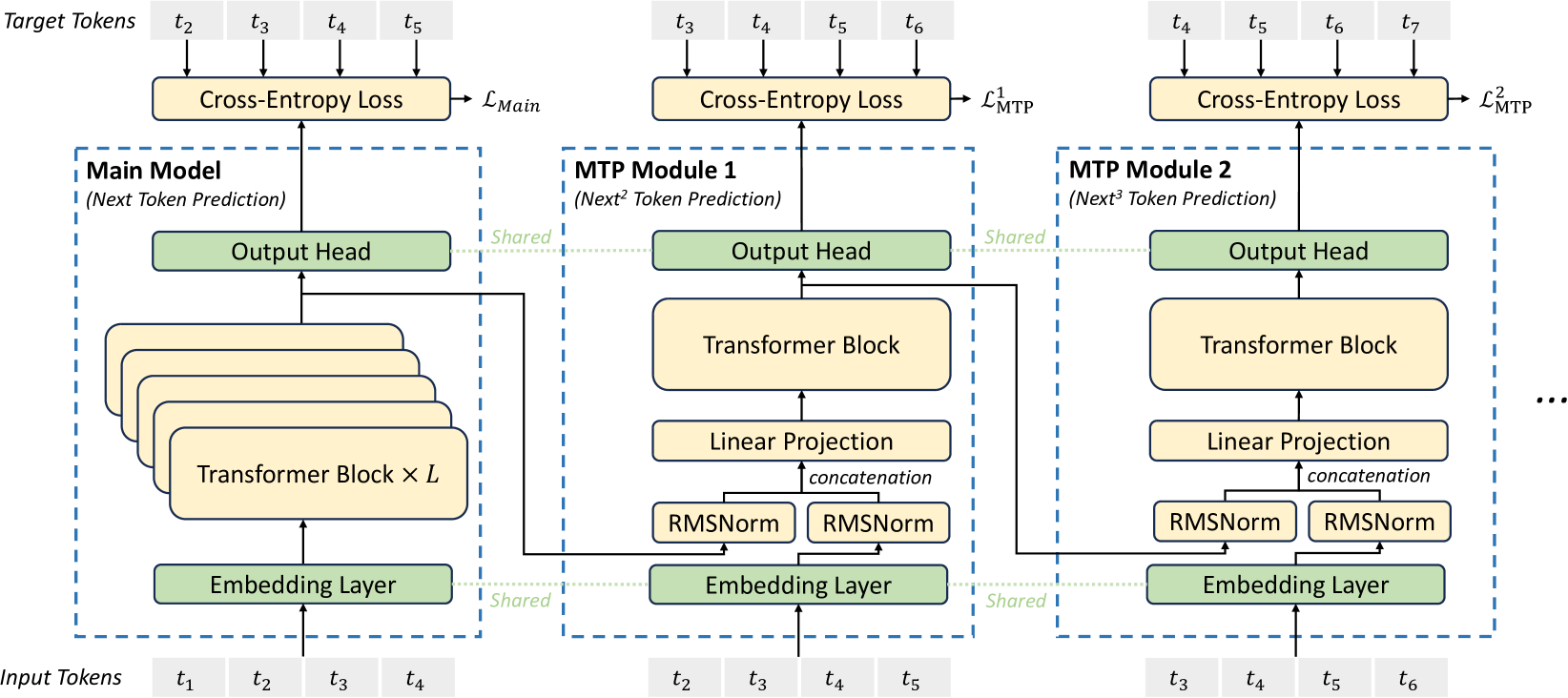
多 token 預測(Multi-Token Prediction,MTP)
DeepSeek V3 採用了多 token 預測訓練目標,為每個深度的每個標記的預測保留完整的 causal chain,旨在提升生成效率和解碼速度。而 DeepSeek V2 沒有使用 MTP ,MTP 讓 DeepSeek V3 的解碼速度提高了 1.8 倍。
DeepSeek-V3 也使用了多 token 預測,能同時預測多個 token,不僅提高模型訓練效率,也可提升 token 產生的速度,模型每秒產生 60 個 token,速度是前一代模型的 3 倍。
另外在訓練階段,DeepSeek 使用了多種硬體和演算法的最佳化,包括 FP8 混合精度訓練框架,以及用於管道化平行的 DualPipe 演算法,來降低模型訓練的成本。
DeepSeek V3 的程式碼目前在 MIT 協議下公開於 GitHub ,模型則根據公司的模型授權提供。
技術參考:
▍後記:創新無關規模
大約 4 個月前,記得自己開始接觸 LLM 這塊領域,那時還很多這個領域的專業名詞都搞不懂,就趕鴨子上架的去跟供應商談規格與需求,想想還真的很有趣 XD
在看這篇 DeepSeek V3 的 technical document 雖然還是很多數學模型搞不清楚,但至少對於那些專業名詞與背後要解決的問題,開始有了概念。
當然,這也很感謝台灣有像李宏毅教授這麼熱血的 AI 領航家,去年修完他的《台大 2024 生成式 AI 導論》課,功力大增收穫滿滿 XD
回到對岸 DeepSeek 這家公司,在美中貿易戰下,反而締造出他們用更低階 GPU 規格,走出一條自己的軟體技術,我看到的是這些年輕學生與企業家在面對困境時所展現的那種韌性。
不得不說對岸這幾年經濟確實不好,也造就他們內需的競爭更加內卷,撇除兩岸問題不談,對岸頂大學生的那種拚勁與狼性真的是碾壓台灣,很值得我們借鏡參考。
最後,我自己是有試玩一下 DeepSeek 的 AI,在繁體中文的回覆上,他的回答雖然是繁中,但語意上會以大陸用語為主,這或許也就是各國都要發展自己 LLM 的原因,畢竟 AI 發展到後面,某種程度也是很吃訓練資料(文化)。
整體而言,DeepSeek 能夠在這麼短時間內,就做出這樣的成績,我自己是覺得相當厲害。儘管在敏感議題上會有回應限制,且整體效能仍稍遜於 ChatGPT 或 Perplexity,但 AI 領域的技術更新速度極快,相信未來會有更令人驚豔的表現。