台大 2024 生成式 AI 導論

台大 2024 生成式 AI 導論
你是否曾經好奇,為什麼 ChatGPT 能夠像人類一樣進行對話,並且理解我們的需求?這堂台大開的「生成式 AI 導論」課程,帶我們深入探索了 AI 的內在運作機制,從最基礎的概念到實際應用,用有趣的上課方式一窺 AI 發展的奧秘。
▍這堂課在說什麼?
這堂課是台大李宏毅(Hung-yi Lee)教授將課程放在 YouTube 上,在學校是一個學期的課程,系統性地介紹了生成式 AI 的發展歷程、運作原理和應用前景。
先科普一下李宏毅這號人物,他是一位相當有名的台灣計算機科學專家,在 2015 年開始在台大教授機器學習課程,當時因為選課人數常常超過 400 人,為了解決教室人數過多的問題,他開始將課程錄製並上傳至 YouTube。
💡 AI 不是在取代人類,而是在幫助人類釋放更多創造力。
而這堂課,就是從最基本的人工智慧概念出發,探討了大型語言模型(LLM)的訓練過程,包括預訓練(Pre-training)、指令微調(Instruction Fine-tuning)和從人類反饋中強化學習(RLHF)等階段。課程不僅介紹了理論知識,還通過實際案例展示了 AI 在現實世界中的應用,特別是在 AI Agent 領域的最新發展。
接下來,將分享這堂課中五個最重要的觀念與心得。
▍大型語言模型的三階段修練
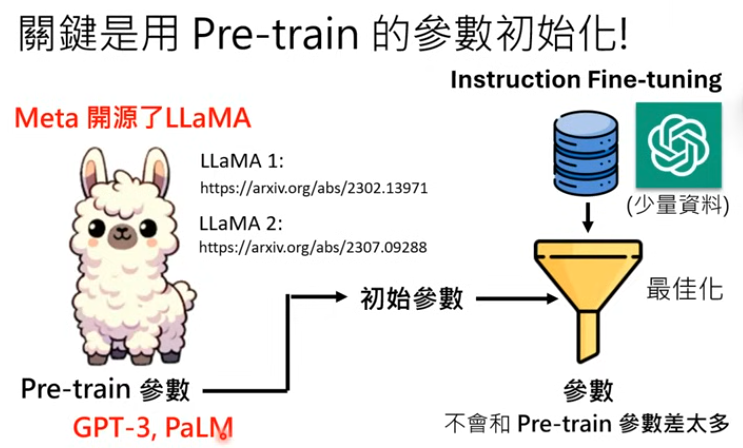
在介紹 LLM 的修練三階段前,老師講了一段很有趣的比喻,其實在 ChatGPT 問世以前,GPT1-3 早在好幾年前就一直有在開發,只是那時候除了模型小以外,資料參數也是隨著每一代的演進,不斷加大,就像下面這張圖。

而這幾堂課可以說是 LLM 的核心基礎,李宏毅教授用一個有趣的比喻來說明,就像武俠小說中的修練過程,大型語言模型的發展也經歷了三個關鍵階段。
-
第一階段是「自我學習」,模型通過大量網路資料積累「內功」
模型運作時,每次生成一個符號(Token),類似將中文字簡化為一個 Token。而語言模型是由數十億個未知參數組成的複雜函式,透過資料訓練來優化這些參數。然後,語言模型就像在玩「文字接龍」一樣,一步步產生文章內容。
而實現這些語言模型的技術基礎,主要是透過機器學習(Machine Learning)和 深度學習(Deep Learning),通過大量的訓練資料 (Training Data) 來進行學習。
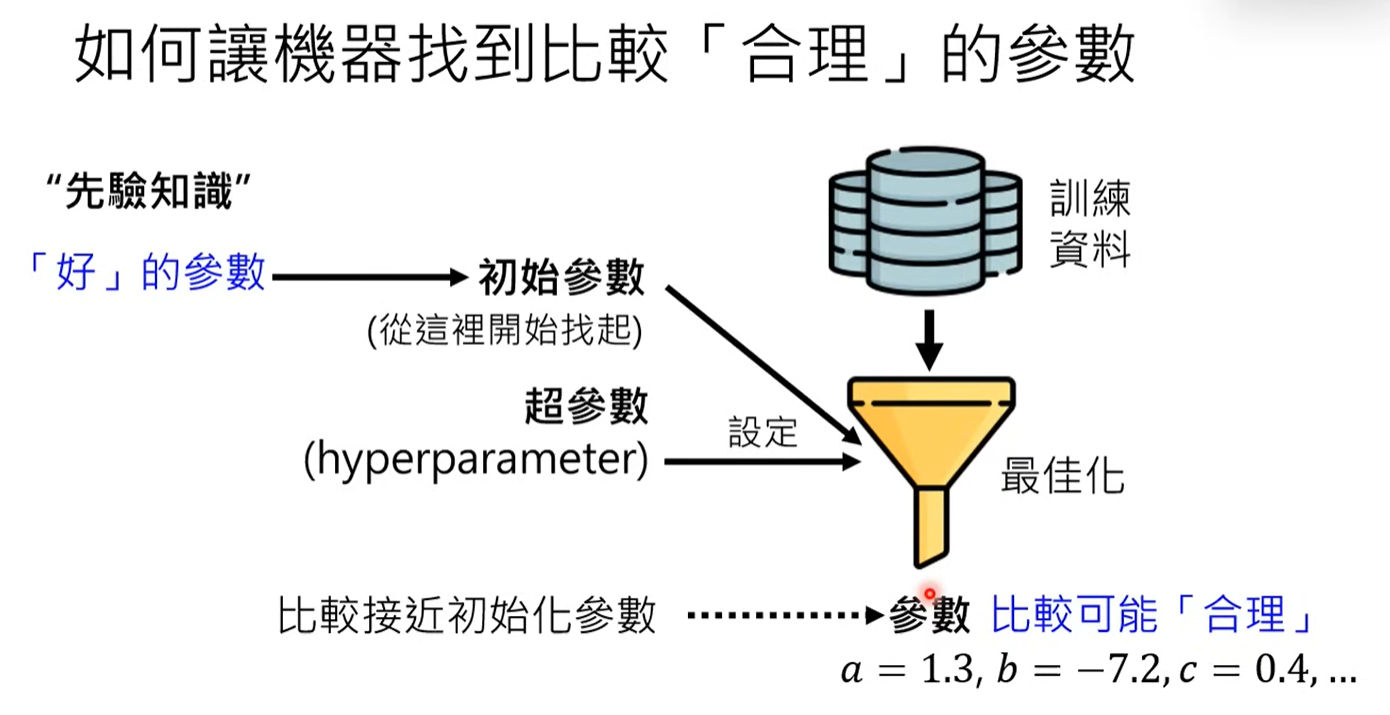
在預訓練(Pre-training)的過程中,如何讓機器能夠找到比較合理的參數,一直是在這個領域大家在探索與解決的問題,其中最佳化(Optimization)與超參數 (Hyperparameter)設定就是在模型訓練過程中的一項挑戰,因為訓練過程中的隨機性可能導致訓練不成功,需要多次嘗試不同的超參數來尋找最佳結果。而這也是為什麼在訓練大型語言模型時,除了需要強大的運算能力外,還需要專業的工程師團隊來進行參數調校。
-
第二階段是「名師指點」,通過人類標註的高質量資料進行微調
在第二階段,說的淺顯易懂就是,透過人類老師的指導,即模型的「微調」(Fine-tuning)。老師提供問題與正確答案的標註資料,模型根據這些資料進行學習。
人類老師需要提供標註資料,這些資料包含使用者問題和 AI 的正確回應,這種過程稱為「督導式學習」(Supervised Learning),是透過大量標註資料進行訓練的過程。在訓練過程中,標註資料對模型能夠正確理解和回應至關重要。
但單靠人類教師的資料來訓練語言模型是有限的,因為資料量不足,無法涵蓋所有可能的情況。
所以這堂課提出了使用第一階段學習所得的初始參數,然後進行「微調」,以改進模型的性能,在這過程中可以使用「Adapter」技術,如LoRA,以減少運算量並保持參數的穩定性。
-
Adapter:在已有的初始參數基礎上進行微調,僅修改少量新增的參數,減少計算量並保持初始參數的穩定。
-
LoRA(Low-Rank Adaptation):LoRA 是 Adapter 技術的一種,專門用來減少運算量,尤其是在資源有限的情況下(如使用免費版Colab)。
-
-
第三階段是「實戰練習」,透過 RLHF(從人類反饋中強化學習)不斷改進
RLHF(Reinforcement Learning from Human Feedback),Human Feedback 顧名思義就是使用者在使用模型時提供反饋,告訴模型哪個答案更好,模型根據這些反饋進行學習和優化。
而這過程使用到的就是增強式學習(Reinforcement Learning),增強學習的目的是提高最終結果的質量,而非關注過程中的每一步。這與第二階段的 Instruction Fine Tuning 最大的差異就是 Instruction Fine Tuning 關注過程,而 RLHF 則關注最終結果的品質。
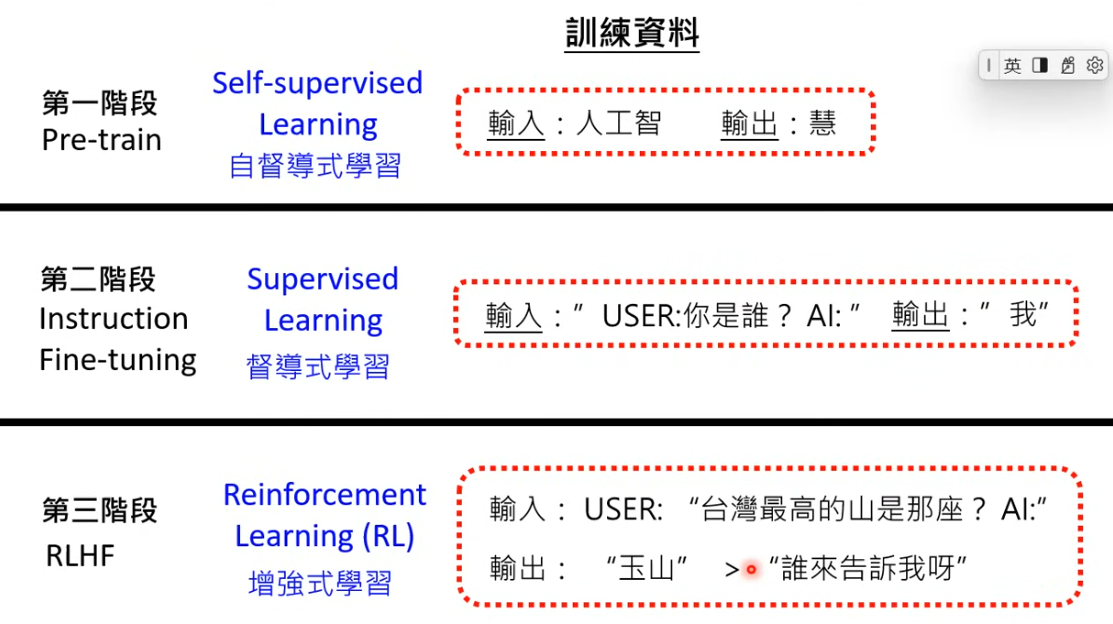
用一張圖在展示 AI 的三階段修練過程,從最初的自我學習階段,到透過人類指導進行微調,最後到實戰練習階段的 RLHF。這種循序漸進的訓練方式,讓 AI 模型能夠不斷進化和完善自己的能力。
▍Transformer:AI 的核心引擎
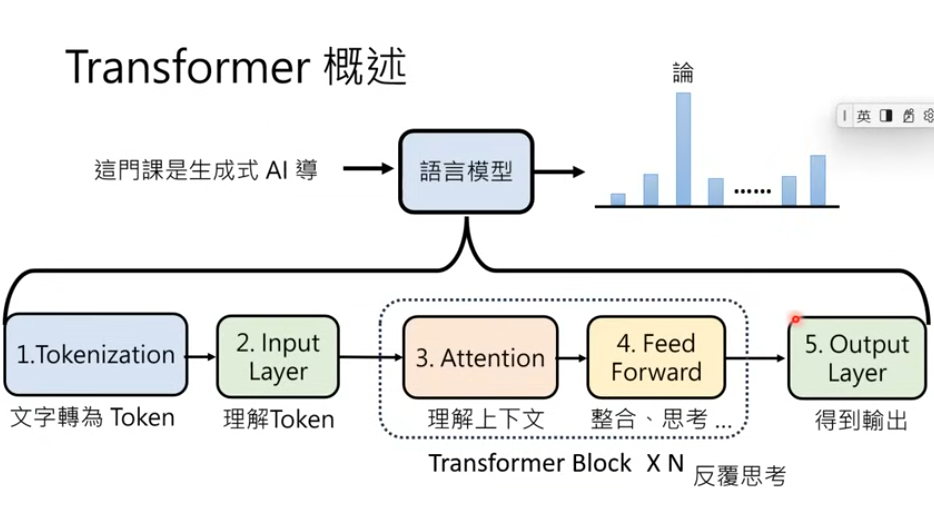
Transformer 架構是現代語言模型的核心,它通過創新的注意力機制(Attention)使 AI 能夠更好地理解文本的上下文關係。
課堂上詳細介紹了 Transformer 的工作原理,從 Token 化處理、位置編碼(Positional Embedding)到多頭注意力機制(Multi-head Attention),展示了 AI 如何將人類語言轉換為機器可以理解和處理的形式。這就像是給 AI 裝上了一個能夠理解人類語言的翻譯器,使其能夠更準確地理解和回應我們的需求。
▍AI Agent 的崛起
課程的最後部分介紹了 AI Agent 的概念和應用。不同於傳統的單一功能 AI,AI Agent 能夠執行多步驟的複雜任務,具有自主規劃和調整計劃的能力。
從 AutoGPT 到實體機器人的應用,AI Agent 展現了驚人的潛力。這意味著 AI 從單純的「工具」轉變為更像「工具人」的智能助手,能夠理解任務目標,制定計劃,並在執行過程中根據環境變化作出調整。

▍後記
我會去上這堂課,除了對生成式 AI 的理論非常感興趣,也因為最近工作上剛好接觸到相關專案。從原本的 AI 小白,到上完課後慢慢建立起基礎概念,這段學習過程真的受益良多。
也多虧李宏毅教授無私的分享,將課程上傳到 YouTube 上,讓我可以札實又有系統的學習整個 AI 課程。不只是學到 AI 的技術原理,更重要的是認識 AI 與人類的關係不是替代,而是協作。
在這個 AI 飛速發展的時代,理解生成式 AI 的運作原理與應用場景已經成為一項重要能力。我們不一定要知道底層技術的開發,但至少要會應用。
現在理工相關科系的畢業生,大多數論文題目都與 AI 有關,但多數人都是從模索中邊做邊學,很少有從理論面去深究每個關鍵決策後面的技術,不得不說這很困難,但如果是要走這塊領域的人,是必經之路。
透過這堂課深入學習 AI 的三階段訓練過程,認識到 AI 的進步也是循序漸進的,需要大量數據、精心調教和持續改進。到通過了解 Transformer 的工作原理,我們看到了 AI 處理人類語言的複雜性和精妙之處。而關於 AI Agent 的發展,相信未來 3-5 年內,這項技術會為我們的生活帶來革命性的改變。